
我们最著名的SDK已更新至第5版:这是自两年最大的OCR技术更新!:
- 基于神经网络的语言模型
- 基于神经网络的拉丁语文字识别
- 拉丁文字的端到端识别
- 基于神经网络的“精确”OCR模式,适用于OCR质量优先的特定情况
- 印章和签名附近文本的识别质量改进
- 基于神经网络的精确条形码识别(超过26种类型)
- 阿拉伯语OCR:基于新神经网络技术的更好识别效果
- 对包含财务数据的表的具体改进
- 使用文档结构增强导出到PowerPoint的功能
- 孟加拉语OCR:添加了支持的语言
OCR技术更新
端到端单词OCR
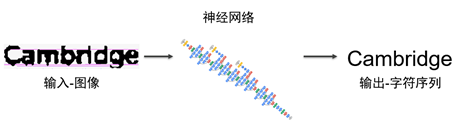
什么时候应该使用端到端OCR?在质量较低的图像上,字符分类艰难的时候。

何不对整文进行端到端OCR?处理高质量的文档的时候,启发式算法具有相同的精度,但速度更快。
|
端到端OCR 要点:
|
 |
深度学习语言模型
| 你能识别这个字母吗? | |
| 这个呢? | |
| 和这个 | |
| 现在识别单词: |  |

为什么识别单词更容易?因为我们知道这个词!它来自英语词汇。
加入有几个适合的词汇?

使用深度学习语言模型来评估所有的结果。
深度学习语言要点
- 我们使用语言模型来纠正OCR错误,使用最接近的单词
- 我们在大型语料库上训练语言模型来理解语言结构
- 深度学习模型有助于收集比词汇表和启发式算法更多的语言信息
“精确”OCR模式
这个更新包括新的基于神经网络的“精确”OCR模式,适用于OCR质量优先的特定情况。
目前,新模式包括:
- 英语语言模式
- 拉丁语言的端到端识别模型
我们建议对发票、协议、收据和ID的低质量或照片图像使用此模式。
印章和签名附近文本的识别质量改进
协议类的文档有大图片,如印章和签名。
通常情况下,印章会阻止机器提取印章附近或之间的文本-文本成为“图片”的一部分,无法识别。
我们在文档分析的文档(协议)模型中添加了特殊的分类器。它检测印章和签名,并把它们从分析中删除,让附近的文字成为可识别的。
测试结果:查找目标对象的准确性:表格,文本,图片,图章,签名 —— 减少了19,3%的错误!
基于神经网络的精确条形码识别
|
我们建立了一个神经网络结构,它能够将图像像素分为两类:条形码和非条形码。 在分割图上选择连通组分;在他们周围建立包围矩形,我们认为矩形作为条形码的假设。在下一个阶段,一个特殊的神经网络对假设值进行解码。 |
 |
PDF功能增强
- PDF文档有各种各样的,有“纯图像”PDF(扫描件)和数字化PDF(有文本层和图片)。FineReader Engine有一个内置的PDF文件自动工作流:它尝试重用PDF文件中的所有信息。
- 但有时PDF文件非常“特殊”,以至于工作流会出错,例如:在一个PDF文件中混合使用纯图像和数字生成的页面。
- 为了解决这种问题并让客户在手动模式下处理此类文件,FineReader Engine提供了灵活的处理功能。
|
数字签名 由于FRDocument可能由多个(多页)图像文件组成,因此可以通过 |
智能字体嵌入 智能字体嵌入模式有助于减少PDF文件的大小。 只要目标标准和用户选择的处理设置允许,它就会自动绕过字体嵌入以降低文件占用空间(默认导出模式:FEM_EmbedSubsetWhenNeeded)。 |
| 检查文本层的质量 |
自适应识别方法 |
内容重用模式 |
|
CheckTextLayer()方法 结合现有的HasTextLayer特性和新的质量分类器;检查PDF文本层并报告其质量是否适合OCR。 |
自适应识别改进并加速PDF处理(默认PDF识别模式:PullXTextAndRecognizeRest)。 |
内容重用模式-CRM_ContentAndPictures。 帮助处理包含混合内容(扫描和文本)的Office文件。 |


